Table of Contents
- 11.1. Enabling/Disabling Filters
- 11.2. Enabling Additional Filters
- 11.3. Filter Reference
- 11.3.1.
ansiquotes.jsFilter - 11.3.2. BidiRemoteSlave (BidiSlave) Filter
- 11.3.3.
breadcrumbs.jsFilter - 11.3.4. CaseTransform Filter
- 11.3.5. ColumnName Filter
- 11.3.6. ConvertStringFromMySQL Filter
- 11.3.7. DatabaseTransform (dbtransform) Filter
- 11.3.8.
dbrename.jsFilter - 11.3.9.
dbselector.jsFilter - 11.3.10.
dbupper.jsFilter - 11.3.11.
dropcolumn.jsFilter - 11.3.12.
dropcomments.jsFilter - 11.3.13.
dropddl.jsFilter - 11.3.14.
dropmetadata.jsFilter - 11.3.15.
droprow.jsFilter - 11.3.16.
dropstatementdata.jsFilter - 11.3.17.
dropsqlmode.jsFilter - 11.3.18.
dropxa.jsFilter - 11.3.19. Dummy Filter
- 11.3.20. EnumToString Filter
- 11.3.21. EventMetadata Filter
- 11.3.22.
foreignkeychecks.jsFilter - 11.3.23. Heartbeat Filter
- 11.3.24.
insertsonly.jsFilter - 11.3.25. Logging Filter
- 11.3.26. MySQLSessionSupport (mysqlsessions) Filter
- 11.3.27. mapcharset Filter
- 11.3.28. NetworkClient Filter
- 11.3.29.
nocreatedbifnotexists.jsFilter - 11.3.30. OptimizeUpdates Filter
- 11.3.31. PrimaryKey Filter
- 11.3.32. PrintEvent Filter
- 11.3.33. Rename Filter
- 11.3.34. Replicate Filter
- 11.3.35. ReplicateColumns Filter
- 11.3.36. Row Add Database Name Filter
- 11.3.37. Row Add Transaction Info Filter
- 11.3.38. SetToString Filter
- 11.3.39. Shard Filter
- 11.3.40.
shardbyseqno.jsFilter - 11.3.41.
shardbytable.jsFilter - 11.3.42. SkipEventByType Filter
- 11.3.43. TimeDelay (delay) Filter
- 11.3.44. TimeDelayMsFilter (delayInMS) Filter
- 11.3.45.
tosingledb.jsFilter - 11.3.46.
truncatetext.jsFilter - 11.3.47.
zerodate2null.jsFilter
- 11.3.1.
- 11.4. Standard JSON Filter Configuration
- 11.5. JavaScript Filters
Filtering operates by applying the filter within one, or more, of the stages configured within the replicator. Stages are the individual steps that occur within a pipeline, that take information from a source (such as MySQL binary log) and write that information to an internal queue, the transaction history log, or apply it to a database. Where the filters are applied ultimately affect how the information is stored, used, or represented to the next stage or pipeline in the system.
For example, a filter that removed out all the tables from a specific database would have different effects depending on the stage it was applied. If the filter was applied on the Extractor before writing the information into the THL, then no Applier could ever access the table data, because the information would never be stored into the THL to be transferred to the Targets. However, if the filter was applied on the Applier, then some Appliers could replicate the table and database information, while other Appliers could choose to ignore them. The filtering process also has an impact on other elements of the system. For example, filtering on the Extractor may reduce network overhead, albeit at a reduction in the flexibility of the data transferred.
In a standard replicator configuration with MySQL, the following stages are configured in the Extractor, as shown in Figure 11.1, “Filters: Pipeline Stages on Extractors”.

Where:
binlog-to-qStageThe
binlog-to-qstage reads information from the MySQL binary log and stores the information within an in-memory queue.q-to-thlStageThe in-memory queue is written out to the THL file on disk.
Within the Applier, the stages configured by default are shown in Figure 11.2, “Filters: Pipeline Stages on Appliers”.
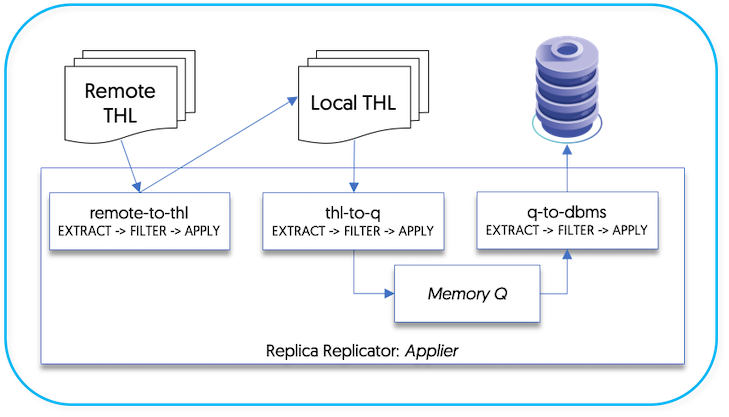
remote-to-thlStageRemote THL information is read from an trext; datasource and written to a local file on disk.
thl-to-qStageThe THL information is read from the file on disk and stored in an in-memory queue.
q-to-dbmsStageThe data from the in-memory queue is written to the target database.
Filters can be applied during any configured stage, and where the filter is applied, alters the content and availability of the information. The staging and filtering mechanism can also be used to apply multiple filters to the data, altering content when it is read and when it is applied.
Where more than one filter is configured for a pipeline, each filter is executed in the order it appears in the configuration. For example, within the following fragment:
... replicator.stage.binlog-to-q.filters=settostring,enumtostring,pkey,colnames ...
settostring is executed first,
followed by enumtostring,
pkey and finally
colnames.
For certain filter combinations this order can be significant. Some filters rely on the information provided by earlier filters.