The JavaScript batchloader enables data to be loaded into datawarehouse and other targets through a simplified JavaScript command script. The script implements specific functions for specification stages for the apply process, from preparation to commit, allowing for internal data, external commands, and other operations to be executed in sequence.
The actual loading process works through the specification of a JavaScript batchload script that defines what operations to perform during each stage of the batchloading process. These mirror the basic steps in the operation of applying the data that is being batchloaded, as shown in Figure 5.3, “Batchloading: JavaScript”.
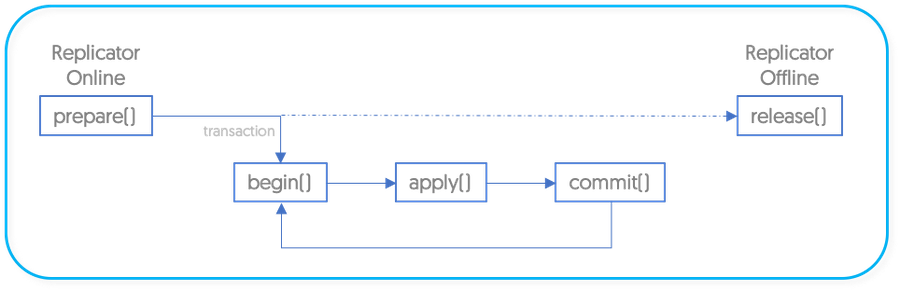
To summarize:
prepare() is called when the replicator goes online
begin() is called before a single transaction starts
apply() is called to copy and load the raw CSV data
commit() is called after the raw data has been loaded
release() is called when the replicator goes offline
The JavaScript batchloader can be used with parallel apply to enable multiple threads to be generated and apply data to the target database. This can be useful in datawarehouse environments where simultaneous loading (and commit) enables effective application of multiple table data into the datawarehouse.
The defined JavaScript methods like prepare, begin, commit, and release are called independently for each environment. This means that you should ensure actions in these methods do not conflict with each other.
CSV files are divided across the scripts. If there is a large number of files that all take about the same time to load and there are three threads (parallelization=3), each individual load script will see about a third of the files. You should therefore not code assumptions that you have seen all tables or CSV files in a single script.
Parallel load script is only recommended for data sources like Hadoop that are idempotent. When applying to a data source that is non-idempotent (for example MySQL or potentially Vertica) you should just use a single thread.