You can replicate data from an existing cluster to a datawarehouse such as Hadoop or Vertica. A replication applier node handles the datawarehouse loading by obtaining THL from the cluster. The configuration of the cluster needs to be changed to be compatible with the required target applier format.
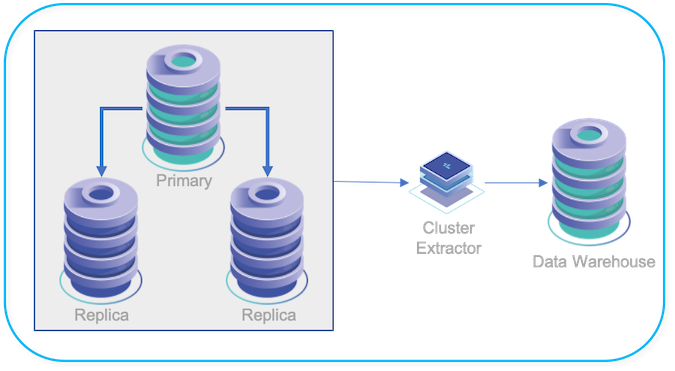
The Cluster-Extractor deployment works by configuring the cluster replication service in heterogeneous mode, and then replicating out to the Appliers that writes into the datawarehouse by using a cluster alias. This ensures that changes to the cluster topology (i.e. Primary switches during a failover or maintenance) still allow replication to continue effectively to your chosen datawarehouse.
The datawarehouse may be installed and running on the same host as the replicator, "Onboard", or on a different host entirely, "Offboard".
Below is a summary of the steps needed to configure the Cluster-Extractor topology, with links to the actual procedures included:
Install or update a cluster, configured to operate in heterogeneous mode.
In our example, the cluster configuration file
/etc/tungsten/tungsten.iniwould contain two stanzas:[defaults]- contains configuration values used by all services.[alpha]- contains cluster configuration parameters, and will usetopology=clusteredto indicate to the tpm command that nodes listed in this stanza are to be acted upon during installation and update operations.
For more details about installing the source cluster, please see Section 3.10.2, “Replicating from a Cluster to a Datawarehouse - Configuring the Cluster Nodes”.
Potentially seed the initial data. For more information about various ways to provision the initial data into the target warehouse, please see Section 3.11, “Migrating and Seeding Data”.
Install the Extractor replicator:
In our example, the Extractor configuration file
/etc/tungsten/tungsten.iniwould contain three stanzas:[defaults]- contains configuration values used by all services.[alpha]- contains the list of cluster nodes for use by the applier service as a source list. This stanza will usetopology=cluster-aliasto ensure that no installation or update action will ever be taken on the listed nodes by the tpm command.[omega]- defines a replicator Applier service that usestopology=cluster-slave. This service will extract THL from the cluster nodes defined in the relay source cluster-alias definition[alpha]and write the events into your chosen datawarehouse.
For more details about installing the replicator, please see Section 3.10.3, “Replicating from a Cluster to a Datawarehouse - Configuring the Cluster-Extractor”.