The fan-in topology is the logical opposite of a fan-out topology. In a fan-in topology, the data from two Sources is combined together on one Target. Fan-in topologies are often in situations where you have satellite databases, maybe for sales or retail operations, and need to combine that information together in a single database for processing.
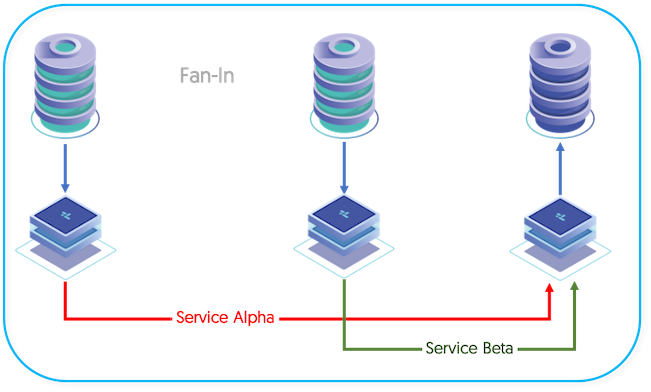
Some additional considerations need to be made when using fan-in topologies:
If the same tables from each each machine are being merged together, it is possible to get collisions in the data where auto increment is used. The effects can be minimized by using increment offsets within the MySQL configuration:
auto-increment-offset = 1 auto-increment-increment = 4Fan-in can work more effectively, and be less prone to problems with the corresponding data by configuring specific tables at different sites. For example, with two sites in New York and San Jose databases and tables can be prefixed with the site name, i.e.
sjc_salesandnyc_sales.Alternatively, a filter can be configured to rename the database
salesdynamically to the corresponding location based tables. See Section 11.3.35, “Rename Filter” for more information.Statement-based replication will work for most instances, but where your statements are updating data dynamically within the statement, in fan-in the information may get increased according to the name of fan-in Sources. Update your configuration file to explicitly use row-based replication by adding the following to your
my.cnffile:binlog-format = rowTriggers can cause problems during fan-in replication if two different statements from each Source and replicated to the Target and cause the operations to be triggered multiple times. Tungsten Replicator cannot prevent triggers from executing on the concentrator host and there is no way to selectively disable triggers. Check at the trigger level whether you are executing on a Source or Target. For more information, see Section C.2.4, “Triggers”.
To create the configuration the Extractors and services must be specified, the topology specification takes care of the actual configuration:
shell> vi /etc/tungsten/tungsten.ini[epsilon]
topology=fan-in
install-directory=/opt/continuent
replication-user=tungsten
replication-password=password
master=host1,host2
members=host1,host2,host3
master-services=alpha,beta
rest-api-admin-user=apiuser
rest-api-admin-password=secret
replicator-rest-api-address=0.0.0.0
Configuration group epsilon
The description of each of the options is shown below; click the icon to hide this detail:
Replication topology for the dataservice.
install-directory=/opt/continuentPath to the directory where the active deployment will be installed. The configured directory will contain the software, THL and relay log information unless configured otherwise.
For databases that require authentication, the username to use when connecting to the database.
The password to be used when connecting to the database using the corresponding
--replication-user.The hostname of the primary (extractor) within the current service.
Hostnames for the dataservice members
Data service names that should be used on each Primary
- Specify the initial Admin Username for API access.
- Specify the initial Admin User Password for API access. Use rest-api-admin-pass in versions prior to 7.1.2.
replicator-rest-api-address=0.0.0.0Address for the API to bind too.
For additional options supported for configuration with tpm, see Chapter 9, The tpm Deployment Command.
If the installation process fails, check the output of the
/tmp/tungsten-configure.log file for
more information about the root cause.
Once the installation has been completed, the service will be started and ready to use.