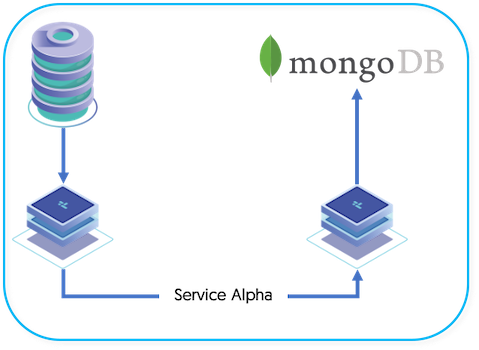
Deployment of a replication to MongoDB service is slightly different to other appliers, there are two parts to the process:
Service Alpha on the Extractor, extracts the information from the MySQL binary log into THL.
Service Alpha on the Applier reads the information from the remote replicator as THL, and applies that to MongoDB.
Basic reformatting and restructuring of the data is performed by translating the structure extracted from one database in row format and restructuring for application in a different format. A filter, the ColumnNameFilter, is used to extract the column names against the extracted row-based information.
With the MongoDB applier, information is extracted from the source database using the row-format, column names and primary keys are identified, and translated to the BSON (Binary JSON) format supported by MongoDB. The fields in the source row are converted to the key/value pairs within the generated BSON.
The transfer operates as follows:
Data is extracted from MySQL using the standard extractor, reading the row change data from the binlog.
The Section 11.3.6, “ColumnName Filter” filter is used to extract column name information from the database. This enables the row-change information to be tagged with the corresponding column information. The data changes, and corresponding row names, are stored in the THL.
The THL information is then applied to MongoDB using the MongoDB applier.
The two replication services can operate on the same machine, (See Section 5.2, “Deploying Multiple Replicators on a Single Host”) or they can be installed on two different machines.
The MongoDB applier can also be used to apply into a MongoDB Atlas instance.
The configuration for MongoDB Atlas is slightly different and follows a typical offboard applier process, similar in style to applying to Amazon Aurora Instances
Specific installation steps for MongoDB Atlas are outlined here Section 4.5.4, “Install MongoDB Atlas Applier”