The Hadoop applier makes use of the JavaScript based batch loading system (see Section 5.5.4, “JavaScript Batchloader Scripts”). This constructs change data from the source-database, and uses this information in combination with any existing data to construct, using Hive, a materialized view. A summary of this basic structure can be seen in Figure 4.8, “Topologies: Hadoop Replication Operation”.
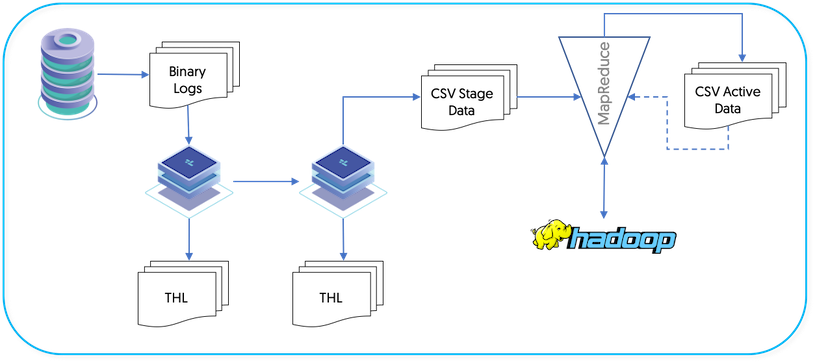
The full replication of information operates as follows:
Data is extracted from the source database using the standard extractor, for example by reading the row change data from the binlog in MySQL.
The
colnamesfilter is used to extract column name information from the database. This enables the row-change information to be tagged with the corresponding column information. The data changes, and corresponding row names, are stored in the THL.The
pkeyfilter is used to extract primary key data from the source tables.On the applier replicator, the THL data is read and written into batch-files in the character-separated value format.
The information in these files is change data, and contains not only the original data, but also metadata about the operation performed (i.e.
INSERT,DELETEorUPDATE, and the primary key of for each table. AllUPDATEstatements are recorded as aDELETEof the existing data, and anINSERTof the new data.A second process uses the CSV stage data and any existing data, to build a materialized view that mirrors the source table data structure.
The staging files created by the replicator are in a specific format that incorporates change and operation information in addition to the original row data.
The format of the files is a character separated values file, with each row separated by a newline, and individual fields separated by the character
0x01. This is supported by Hive as a native value separator.The content of the file consists of the full row data extracted from the source, plus metadata describing the operation for each row, the sequence number, and then the full row information.
| Operation | Sequence No | Unique Row | Commit TimeStamp | Table-specific primary key | Table-column |
|---|---|---|---|---|---|
| I (Insert) or D (Delete) |
SEQNO that generated this row
| Unique row ID within the batch | The commit timestamp of the original transaction, which can be used for partitioning |
For example, the MySQL row:
| 3 | #1 Single | 2006 | Cats and Dogs (#1.4) |
Is represented within the staging files generated as:
I^A1318^A1^A2017-06-07 09:22:28.000^A3^A3^A#1 Single^A2006^ACats and Dogs (#1.4)
The character separator, and whether to use quoting, are configurable
within the replicator when it is deployed. The default is to use a newline
character for records, and the 0x01
character for fields. For more information on these fields and how they
can be configured, see
Section 5.5.7, “Supported CSV Formats”.
On the Hadoop host, information is stored into a number of locations within the HDFS during the data transfer:
Table 4.2. Hadoop Replication Directory Locations
| Directory/File | Description |
|---|---|
/user/USERNAME
| Top-level directory for Tungsten Replicator information, using the configured replication user. |
/user/tungsten/metadata
| Location for metadata related to the replication operation |
/user/tungsten/metadata/
| The directory (named after the servicename of the replicator service) that holds service-specific metadata |
/user/tungsten/staging
| Directory of the data transferred |
/user/tungsten/staging/
| Directory of the data transferred from a specific servicename. |
/user/tungsten/staging/
| Directory of the data transferred specific to a database. |
/user/tungsten/staging/
| Directory of the data transferred specific to a table. |
/user/tungsten/staging/
| Filename of a single file of the data transferred for a specific table and database. |
Files are automatically created, named according to the parent table name, and the starting Tungsten Replicator sequence number for each file that is transferred. The size of the files is determined by the batch and commit parameters. For example, in the truncated list of files below displayed using the hadoop fs command,
shell> hadoop fs -ls /user/tungsten/staging/hadoop/chicago
Found 66 items
-rw-r--r-- 3 cloudera cloudera 1270236 2020-01-13 06:58 /user/tungsten/staging/alpha/hadoop/chicago/chicago-10.csv
-rw-r--r-- 3 cloudera cloudera 10274189 2020-01-13 08:33 /user/tungsten/staging/alpha/hadoop/chicago/chicago-103.csv
-rw-r--r-- 3 cloudera cloudera 1275832 2020-01-13 08:33 /user/tungsten/staging/alpha/hadoop/chicago/chicago-104.csv
-rw-r--r-- 3 cloudera cloudera 1275411 2020-01-13 08:33 /user/tungsten/staging/alpha/hadoop/chicago/chicago-105.csv
-rw-r--r-- 3 cloudera cloudera 10370471 2020-01-13 08:33 /user/tungsten/staging/alpha/hadoop/chicago/chicago-113.csv
-rw-r--r-- 3 cloudera cloudera 1279435 2020-01-13 08:33 /user/tungsten/staging/alpha/hadoop/chicago/chicago-114.csv
-rw-r--r-- 3 cloudera cloudera 2544062 2020-01-13 06:58 /user/tungsten/staging/alpha/hadoop/chicago/chicago-12.csv
-rw-r--r-- 3 cloudera cloudera 11694202 2020-01-13 08:33 /user/tungsten/staging/alpha/hadoop/chicago/chicago-123.csv
-rw-r--r-- 3 cloudera cloudera 1279072 2020-01-13 08:34 /user/tungsten/staging/alpha/hadoop/chicago/chicago-124.csv
-rw-r--r-- 3 cloudera cloudera 2570481 2020-01-13 08:34 /user/tungsten/staging/alpha/hadoop/chicago/chicago-126.csv
-rw-r--r-- 3 cloudera cloudera 9073627 2020-01-13 08:34 /user/tungsten/staging/alpha/hadoop/chicago/chicago-133.csv
-rw-r--r-- 3 cloudera cloudera 1279708 2020-01-13 08:34 /user/tungsten/staging/alpha/hadoop/chicago/chicago-134.csv
...The individual file numbers will not be sequential, as they will depend on the sequence number, batch size and range of tables transferred.