The Tungsten Cluster default position is to protect the integrity of the data. Sometimes this means that a failover may be delayed. It is more important to have all the data than for the write Primary to be available. This behavior is configurable.
When the Manager quorum invokes a failover automatically, there are various states that each replication stream may be in that must be taken into account by the Manager layer as it coordinates the failover.
This is due to the loosely-coupled, asynchronous nature of Tungsten Replicator.
The multiple scenarios regarding the state of the data are described below, along with how to locate any associated events:
First, the normal situation - all events in the binary logs have been extracted into the Primary THL, all Primary THL has been transferred to all Replica nodes, and all THL on the Replica nodes has been fully applied to all Replica databases.
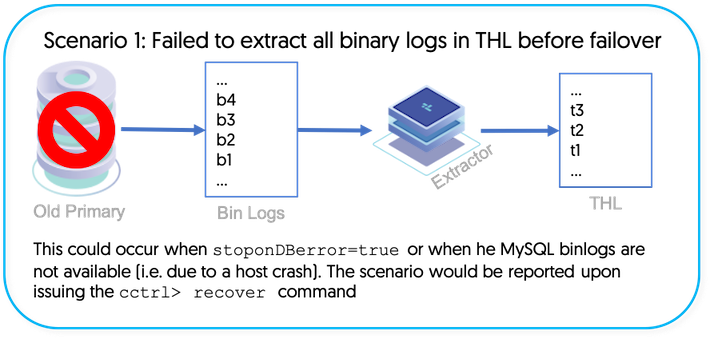
Scenario 1 - There are orphaned MySQL binary log events on the old Primary that were not extracted into THL before a failover occurred.
This could occur when
stoponDBerror=trueor when the MySQL binlogs are not available (i.e. due to a host crash). The scenario would be reported upon issuing the cctrl recover command.The tungsten_find_orphaned script can help locate orphaned binary log events that did not make it to the THL on the old Primary before a failover. For more information, please see Scenario 1 in Section 9.25, “The tungsten_find_orphaned Command”.
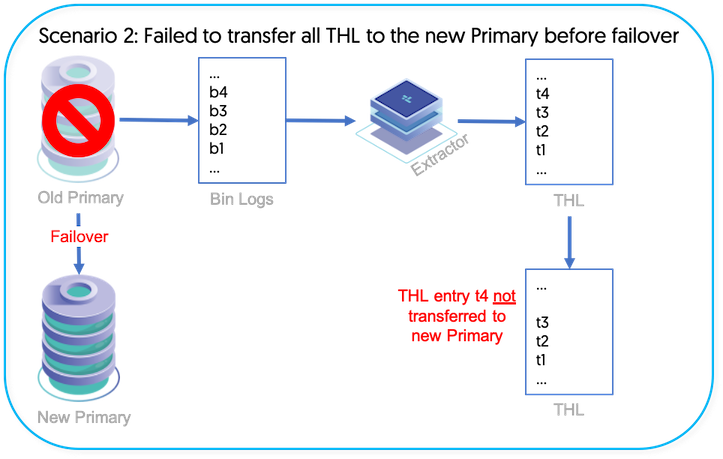
Scenario 2 - There is orphaned THL left on the old Primary that did not make it to the new Primary
The tungsten_find_orphaned script can help locate orphaned Primary THL left on the old Primary that did not make it to the new Primary before a failover. For more information, please see Scenario 2 in Section 9.25, “The tungsten_find_orphaned Command”.
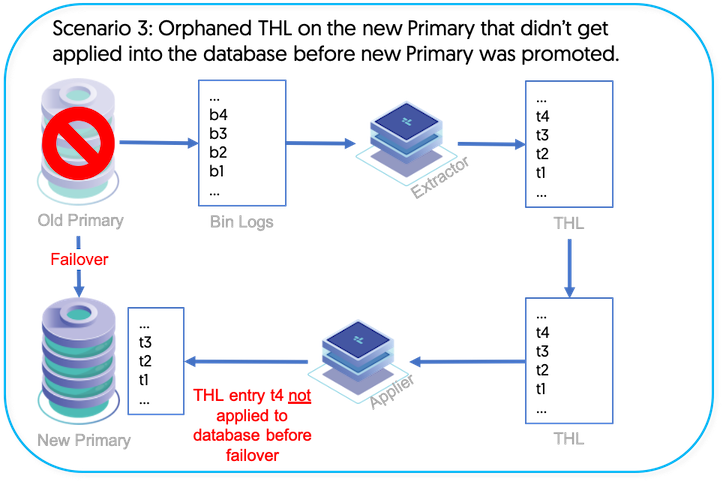
Scenario 3 - There is orphaned Replica THL on the new Primary node that did not get applied into the database before getting promoted to Primary role
The tungsten_find_orphaned script can help locate orphaned Replica THL on the new Primary node that did not get applied into the database before getting promoted to Primary role during a failover. For more information, please see Scenario 3 in Section 9.25, “The tungsten_find_orphaned Command”.
The Tungsten Manager is able to detect un-extracted, desirable binary log events when recovering the old Primary via cctrl after a failover.
The cctrl recover command will fail if:
any unextracted binlog events exist on the old Primary that we are trying to recover (Scenario 1)
the old Primary THL contains more events than the Replica that will be promoted to a new Primary (Scenario 2)
In this case, the cctrl recover command will display text similar to the following:
Recovery failed because the failed master has unextracted events in
the binlog. Please run the tungsten_find_orphaned script to inspect
this events. Provided you have a recent backup available, you can
try to restore the data source by issuing the following command:
datasource {hostname} restore
Please consult the user manual at:
https://docs.continuent.com/tungsten-clustering-6.1/operations-restore.htmlThe tungsten_find_orphaned script is designed to locate orphaned events. For more information, please see Section 9.25, “The tungsten_find_orphaned Command”.
The Manager and Replicator behave in concert when MySQL dies on the Primary
node. When this happens, the replicator is unable to update the
trep_commit_seqno table any longer, and therefore must
either abort extraction or continue extracting without recording the
extracted position into the database.
By default, the Manager will delay failover until all remaining events have been extracted from the binary logs on the failing Primary node as a way to protect data integrity.
This behavior is configurable via the following setting, shown with the
default of false:
property=replicator.store.thl.stopOnDBError=false
Failover will only continue once:
all available events are completely read from the binary logs on the Primary node
all events have reached the Replicas
When
property=replicator.store.thl.stopOnDBError=true,
then the Replicator will stop extracting once it is unable to update the
trep_commit_seqno table in MySQL, and the Manager will
perform the failover without waiting, at the risk of possible data loss
due to leaving binlog events behind. All such situations are logged.
For use cases where failover speed is more important than data accuracy,
those NOT willing to wait for long failover can set
property=replicator.store.thl.stopOnDBError=true and still use
tungsten_find_orphaned to manually analyze and perform
the data recovery. For more information, please see
Section 9.25, “The tungsten_find_orphaned Command”.
During a failover, the manager will wait until the Replica that is the candidate for promotion to Primary has applied all stored THL events before promoting that node to Primary.
This wait time can be configured via the
property=manager.failover.thl.apply.wait.timeout=0 property.
The default value is 0, which means "wait indefinitely until all stored THL events are applied".
Any value other than zero invites data loss due to the fact that once the Replica is promoted to Primary, any unapplied stored events in the THL will be ignored, and therefore lost.
Whenever a failover occurs, the Replica with most events stored in the local THL is selected so that when the events are eventually applied, the data is as close to the original Primary as possible with the least number of events missed.
That is usually, but not always, the most up-to-date Replica, which is the one with the most events applied.
There should be a good balance between the value for
property=manager.failover.thl.apply.wait.timeout and the value for
property=policy.slave.promotion.latency.threshold=900, which is
the "maximum Replica latency" - this means the number of seconds to which a
Replica must be current with the Primary in order to qualify as a candidate
for failover. The default is 15 minutes (900 seconds).