Deploying the Hadoop Applier
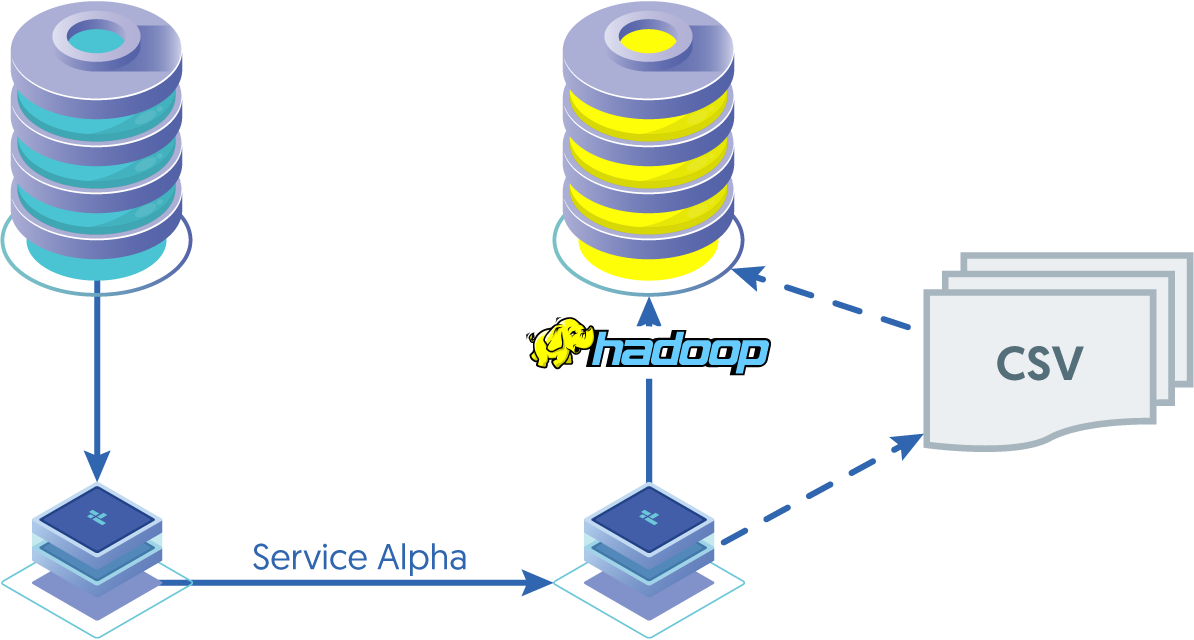
Replicating data into Hadoop is achieved by generating character-separated values from ROW-based information that is applied directly to the Hadoop HDFS using a batch loading process. Files are written directly to the HDFS using the Hadoop client libraries. A separate process is then used to merge existing data, and the changed information extracted from the Source database.
Deployment of the Hadoop replication is similar to other heterogeneous installations; two separate installations are created:
- Service Alpha on the extractor, extracts the information from the MySQL binary log into THL.
- Service Alpha on the applier, reads the information from the remote replicator as THL, applying it to Hadoop. The applier works in two stages
Basic requirements for replication into Hadoop:
- Hadoop Replication is supported on the following Hadoop distributions and releases:
- Cloudera Enterprise 4.4, Cloudera Enterprise 5.0 (Certified) up to Cloudera Enterprise 5.8
- HortonWorks DataPlatform 2.0
- Amazon Elastic MapReduce
- IBM InfoSphere BigInsights 2.1 and 3.0
- MapR 3.0, 3.1, and 5.x
- Pivotal HD 2.0
- Apache Hadoop 2.1.0, 2.2.0
- Source tables must have primary keys. Without a primary key, Tungsten Replicator is unable to determine the row to be updated when the data reaches Hadoop.